April 13, 20263-4 weeks
Promptura — Iterative Prompt Optimization System for Multimodal AI
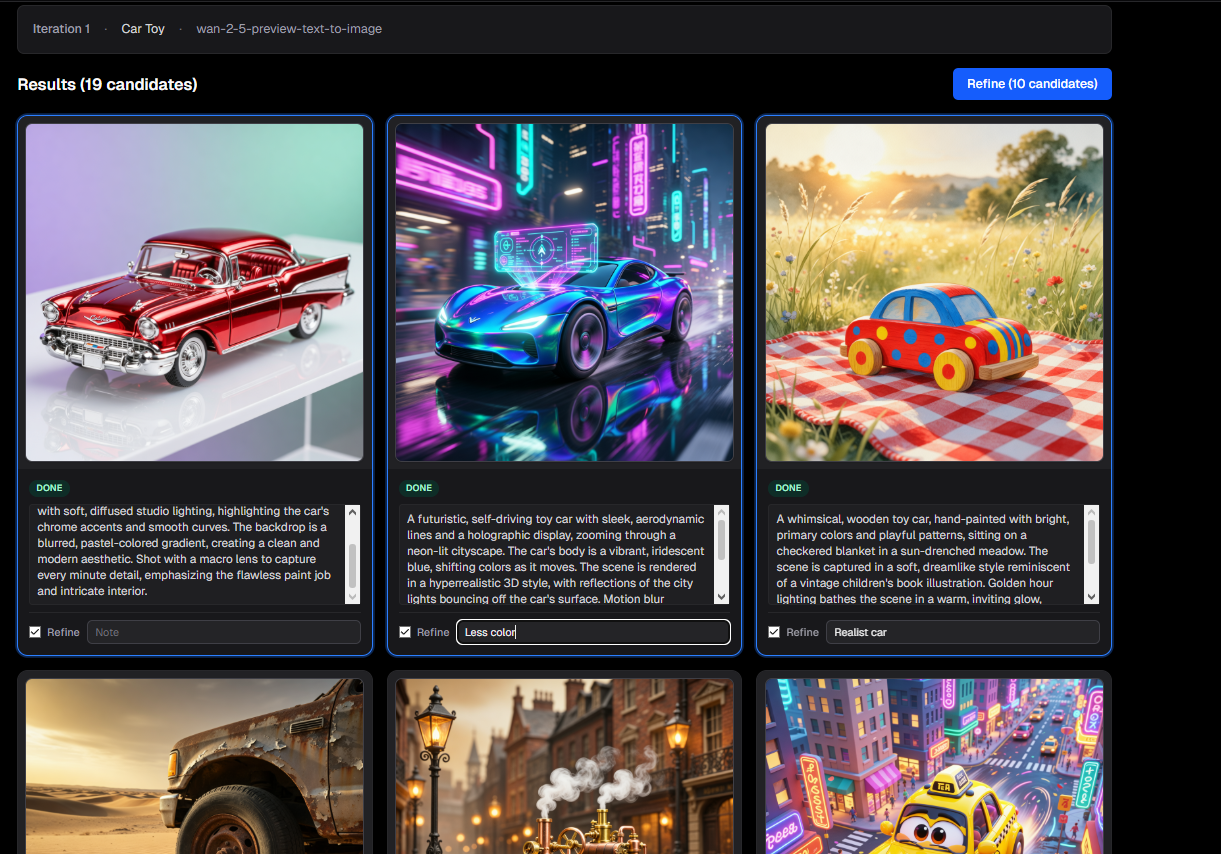
Promptura is a feedback-driven workflow system for multimodal generation. Users define a task goal, the system generates candidate prompts, executes them across selected providers, and uses output selection plus user feedback to refine the next iteration.
- Role
- Designed and built the system end-to-end, including product logic, backend architecture, provider abstraction, and AI workflow orchestration.
- Stack
- Next.js · TypeScript · Prisma · PostgreSQL · NextAuth · Gemini API · fal.ai · EachLabs
- Links
- LiveRepository
Problem
Working with generative models requires repeated trial-and-error, where the same intent produces inconsistent outputs across different models and providers. Users must manually rewrite prompts, deal with provider-specific quirks, and evaluate results without a structured feedback loop, making prompt quality the primary bottleneck.
Solution
Built an iteration-based system that converts prompt engineering into a structured optimization loop. Users define a task goal, the system generates multiple candidate prompts, executes them across selected models, and refines future iterations based on actual outputs. Prompt generation is centralized using Gemini, while execution is handled through provider-agnostic integrations.
Decisions
- Replaced prompt textbox with iteration-first workflow to reduce user complexity
- Centralized prompt generation using Gemini instead of provider-side prompting
- Introduced ModelSpec abstraction to decouple system from provider schemas
- Chose polling over streaming to reduce system complexity and avoid real-time state synchronization issues
- Intentionally hid model-specific parameters to prevent provider complexity from leaking into the user experience
Architecture highlights
- Iteration-based prompt optimization loop replacing manual prompt workflows
- Provider-agnostic execution layer supporting multiple model providers
- Schema-driven ModelSpec generation for modality and asset inference
- Separation of prompt generation (Gemini) and execution (external providers)
- Persistent iteration and run tracking with observable execution lifecycle
- Polling-based execution flow for status tracking and reliability
Outcomes
- Built a working system executing prompts across multiple providers
- Reduced manual prompt trial-and-error into a structured iteration loop
- Enabled consistent prompt generation independent of execution provider
- Established a scalable architecture for adding new models and modalities